
 Меню
Меню





 Все темы
Все темы
Картирование протеома человека выполнено на 90%
План проекта Human Proteom Project выполнен на 90,4%: количество белков, идентифицированных с высоким уровнем достоверности, составило 17 874, при том что в референсной базе белок-кодирующих генов содержится 19 773 записи. В Nature Communications рассказали об особенностях работы и достижениях проекта.
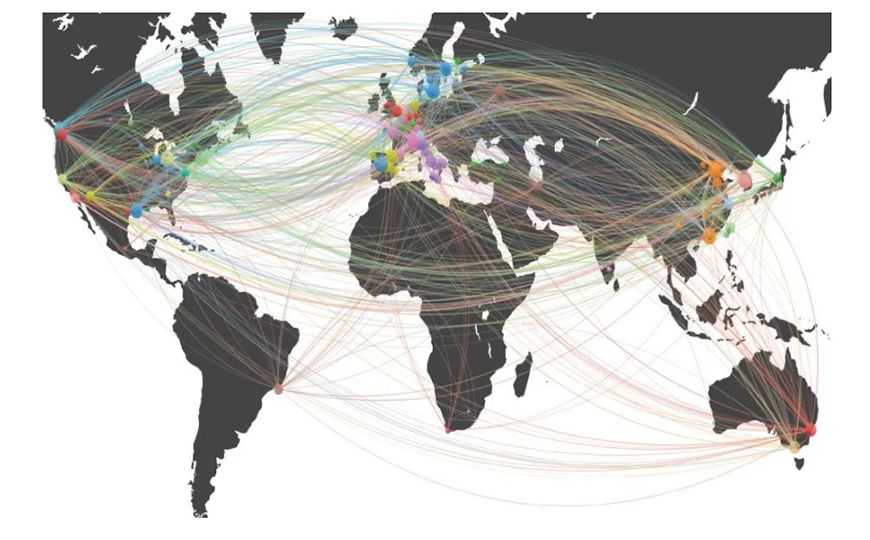
Credit: Adhikari, et al., 2020; DOI: 10.1038/s41467-020-19045-9 | CC BY 4.0
Проект Human Proteome Project (HPP) был запущен в 2010 году. Он стал основой для международного сотрудничества и обмена данными, а также повысил качество и точность аннотации человеческого протеома. За 10 лет было налажено сотрудничество между различными компаниями, разработаны критерии составления базы данных, проведен повторный анализ ранее депонированных данных. В Nature Communications опубликована статья, посвященная особенностям работы и главным достижениям проекта.
Чтобы достоверно каталогизировать протеом человека с учетом посттрансляционных модификаций, вариантов сплайсинга, взаимодействия белков и их функций, HPP сформулировал следующие задачи: установление строгих стандартов для занесения белка в базу, идентификация более одного продукта кодирующего белок гена и обнаружение экспрессии недостающих белков. Еще одна цель проекта —интеграция протеомики в многопрофильные исследования, связанные с науками о жизни и медициной.
Две главных инициативы HPP на сегодняшний день — хромосомно-ориентированная (C-HPP; 25 команд) и ориентированная на биологию и заболевания (B/D-HPP; 19 команд) — опираются на четыре главных подхода: регистрация белка с помощью антител, масс-спектрометрический анализ, работа с базами данных и изучение информации о патологиях.
HPP полагается на систему, разработанную проектами neXtProt и UniProtKB, которая выделяет пять уровней уверенности в существовании белка (PE, от PE1 до PE5). Цель HPP — получение точных, строго подтвержденных (уровень PE1) данных о существовании того или иного пептида. С 2013 года HPP и база neXtProt работают в коллаборации и выпускают совместные ежегодные отчеты.
Количество белков, идентифицированных с высоким уровнем надежности (PE1), с 2011 года увеличилось с 13 588 до 17 874. В референсной базе neXtProt содержится 19 773 белок-кодирующих генов. Это значит, что план проекта выполнен на 90,4%, и черновой вариант протеомной карты человека готов.
В статье также представлены конкретные примеры, демонстрирующие, что протеомика вместе с геномикой и другими омиками станут неотъемлемым компонентом будущих открытий в области биологии и медицины, в том числе в контексте COVID-19.
Источник
Adhikari, et al. // A high-stringency blueprint of the human proteome. // Nature Communications 11, 5301 (2020); DOI: 10.1038/s41467-020-19045-9

Вам будет интересно
 48
48
 0
0


 57
0
57
0








