
 Меню
Меню





 Все темы
Все темы
Система на основе машинного обучения выявляет рак яичника по метаболитам крови
Диагностика рака на ранних стадиях бывает затруднена в связи с отсутствием клинических проявлений, быстрым прогрессированием заболевания и молекулярной гетерогенностью рака. Ученые из США разработали диагностическую систему, позволяющую с точностью от 93% выявлять рак яичников как на ранних, так и на поздних стадиях. В основе метода — машинное обучение, а в качестве входных данных использовали метаболом сыворотки крови.
Ранняя диагностика — важнейший фактор для успешного лечения рака. Однако для некоторых видов онкологических заболеваний, в том числе рака яичников, она затруднена в связи с отсутствием клинических проявлений на ранних этапах и быстрым прогрессированием опухоли. Кроме того, рак очень разнообразен на молекулярном уровне, из-за чего бывает сложно подобрать диагностические биомаркеры. Ученые из США представили тест-систему для выявления вероятности рака яичников. Для анализа они использовали сыворотку крови, метаболом которой анализировался с помощью модели машинного обучения, а на выходе получали вероятность наличия рака яичников в баллах от -2 до 2.
В исследовании по разработке тест-системы приняли участие 431 пациентка с раком яичников и 133 здоровые женщины. Образцы их сыворотки крови анализировали методом сверхпроизводительной жидкостной хроматографии в сочетании с тандемной масс-спектрометрией (UPLC-MS/MS). Каждый из образцов изучали при четырех различных режимах UPLC-MS/MS. В результате были получены четыре набора данных о метаболомах участниц исследования.
Затем ученые проанализировали точность прогнозирования пяти классификаторов машинного обучения для каждого из четырех наборов данных. Они применяли классификатор логистической регрессии (LRC), метод случайного леса (RFC), метод опорных векторов (SVM), метод k-ближайших соседей (KNN) и адаптивный бустинг (ADA). На основе этих пяти независимых методов исследователи получили консенсусный классификатор.
В первую очередь авторы определили наиболее важные метаболиты, ассоциированные с вероятностью развития рака яичника, с помощью инструментов машинного обучения. Каждому метаболиту присваивали относительную частоту и относительные уровни вклада (то есть значимость для развития заболевания). В большинстве наборов данных самые значимые метаболиты имели наибольшую частоту, однако один из четырех наборов данных показал наличие низкочастотных особенностей с высокой значимостью.
Выявленным особенностям метаболомов присвоили веса — комбинированный показатель частоты и значимости. Метаболиты ранжировали и объединили в ранговые группы, а затем классифицировали по предполагаемым функциям на основе базы данных метаболомов человека. С помощью этой базы данных удалось определить только около 7% метаболитов, остальные остались неаннотированными.
Далее имеющиеся наборы данных сжимали, а затем оценивали способность каждого из пяти классификаторов идентифицировать образцы, полученные от пациента с раком или от здорового человека. При оценке опирались на четыре критерия: положительная прогностическая ценность, отрицательная прогностическая ценность, среднее гармоническое точности и полноты показателя и коэффициент корреляции Мэтьюса, который отражает связь между наблюдаемым и предсказанным значением бинарного классификатора. Для всех четырех наборов данных консенсусный классификатор показал низкий уровень ложноотрицательных результатов (2–3%) и несколько более высокий уровень ложноположительных результатов (от 11 до 17%). Общая производительность для всех наборов данных оказалась достаточно высокой, показав положительную прогностическую ценность от 93% и выше.
В результате анализа авторы получали средний балл от -2 до 2, который говорит об отсутствии (отрицательные значения) или наличии (положительные значения) рака яичников. Объединение четырех наборов данных позволило получать более точные результаты. 97% образцов, полученных от пациенток с раком яичников, получили оценку 1,0-2,0 балла, а доля ложноотрицательных результатов составила 0%. Напротив, только 83% образцов здоровых женщин попали в диапазон от -0,2 до -0,1, что говорит о том, что классификатор лучше определяет наличие рака, чем его отсутствие.
Разработанная диагностическая система оказалась эффективной вне зависимости от возраста пациентки и стадии развития заболевания. На ранних стадиях эффективность анализа составила 98%, на поздних — 92,7%.
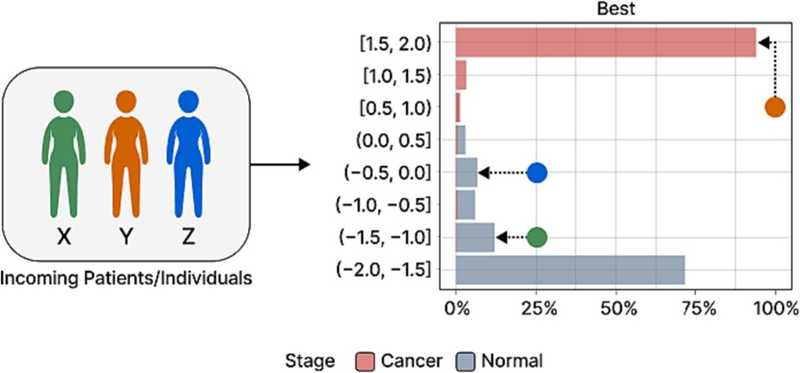 При диагностике рака яичников, основанной на предложенном методе машинного обучения, возможно несколько сценариев. Профиль метаболитов X попадает в диапазон баллов, где ошибочный диагноз маловероятен, что позволяет с уверенностью исключить рак. Профиль метаболитов Y лежит в диапазоне, в котором у 94 % других людей с таким показателем был диагностирован рак. И наконец, определение онкологического статуса Z может оказаться сложной задачей, поскольку в этом диапазоне баллов всего несколько образцов, и он находится в середине распределения.
При диагностике рака яичников, основанной на предложенном методе машинного обучения, возможно несколько сценариев. Профиль метаболитов X попадает в диапазон баллов, где ошибочный диагноз маловероятен, что позволяет с уверенностью исключить рак. Профиль метаболитов Y лежит в диапазоне, в котором у 94 % других людей с таким показателем был диагностирован рак. И наконец, определение онкологического статуса Z может оказаться сложной задачей, поскольку в этом диапазоне баллов всего несколько образцов, и он находится в середине распределения.Credit:
Gynecologic Oncology (2024). DOI: 10.1016/j.ygyno.2023.12.030 | CC BY-NC-ND
Таким образом, исследователи предложили диагностическую систему, которая с помощью инструментов машинного обучения определяет вероятность наличия рака яичников по метаболому образца сыворотки крови. Такая тест-система может стать вспомогательным инструментом для ранней диагностики рака, повысив эффективность выявления и лечения онкологических заболеваний.
Модель глубокого обучения поможет выявить клетки, склонные к метастазированию
Источник
Dongjo Ban et al. A personalized probabilistic approach to ovarian cancer diagnostics // Gynecologic Oncology (2024). DOI: 10.1016/j.ygyno.2023.12.030
Вам будет интересно
 47
47
 0
0


 101
0
101
0

 157
0
157
0







