Меню
Меню





 Все темы
Все темы
Закрепление поведения зависит от двух разных дофаминовых сигналов
Мозг может запоминать не только полезные, но и любые часто повторяющиеся действия. Авторы статьи в Nature описали новый тип дофаминового сигнала в мозге мышей, который помогает животным обучаться повторять действия, ранее приведшие к успеху. Исследование показало, что сигналы дофаминовых нейронов в стриатуме помогают закреплять повторяющиеся движения, даже если они не приносят вознаграждения. Эта система дополняется уже известным дофаминовым механизмом, который стимулирует выполнение именно вознаграждаемых действий.
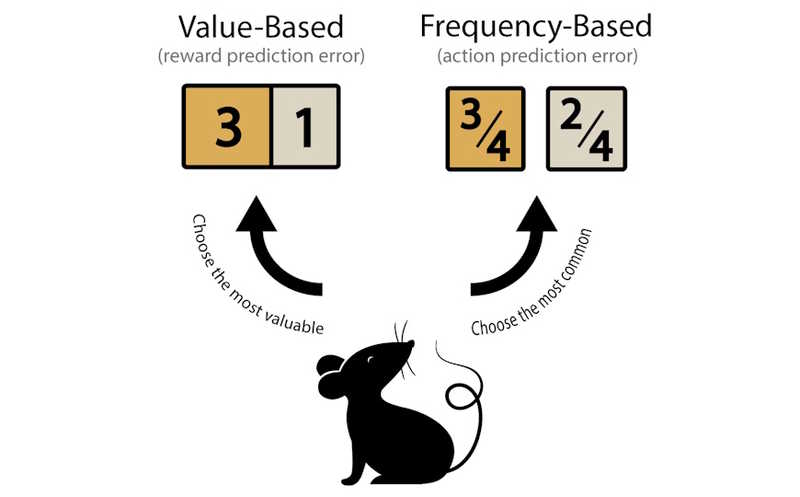
Поведение животных и людей основано на двух важных стратегиях: стремлении к вознаграждению и повторении действий, которые ранее приносили успех. Считалось, что за обе стратегии отвечает один механизм — дофаминовая система вознаграждения, которая кодирует «ошибку предсказания вознаграждения» (reward prediction error, RPE): если результат лучше ожиданий, дофамин «поощряет» мозг, усиливая связь между действием и наградой. Группа под руководством ученых из Университетского колледжа Лондона обнаружила другой тип сигнала — ошибку предсказания действия (action prediction error, APE). Этот сигнал определяет, насколько предсказуемым оказалось само движение, и помогает закрепить его вне зависимости от результата.
Ученые задались вопросом: как мозг обучается стабильным ассоциациям, например, когда мы автоматически реагируем на знакомый звук или ситуацию? Чтобы изучить этот феномен, исследователи обучали мышей различать звуковые сигналы и выбирать по ним выход из лабиринта. При этом они наблюдали за активностью дофаминовых нейронов в разных зонах полосатого тела (стриатума) — в том числе его хвостовой части, которая участвует в формировании условных реакций на привычные сигналы.
Исследователи обучили мышей различать звуковые сигналы и выбирать левый или правый выход из лабиринта в зависимости от частоты звука. Параллельно они отслеживали колебания уровня дофамина в хвостовой части стриатума с помощью флуоресцентного сенсора dLight1.1, доставленного в клетки вирусными векторами. Чтобы понять, с чем именно связан дофаминовый сигнал — с движением, звуком или наградой — исследователи применили регрессионный анализ. Он позволил разложить сигнал на компоненты, соответствующие разным событиям задачи: подаче звука, началу выбора и получению результата.
Авторы работы заметили, что в начале обучения всплески дофамина в хвостовой части стриатума возникали при движении мышей в определенную сторону и были особенно выражены, когда выбор был менее предсказуем. Но по мере того, как животные осваивали задание и их поведение стабилизировалось, сигналы ослабевали. Это согласуется с идеей, что хвост стриатума реагирует не на само движение, а на ошибку предсказания: дофамин высвобождается тогда, когда мозг еще не уверен, какое действие будет совершено. Такой сигнал как бы отмечает поведение, которое пока не стало привычным, и способствует его повторению. Когда же действие закрепляется — дофаминовый всплеск больше не нужен: поведение перешло в категорию «по умолчанию» и поддерживается без дополнительного поощрения.
Ученые дополнительно проверили, действительно ли дофаминовый сигнал в хвостовой части стриатума может закреплять действия. Для этого они использовали метод оптогенетики: в нейроны доставляли светочувствительный белок каналородопсин ChR2. Его активация лазером вызывала искусственное высвобождение дофамина в момент принятия решения. Это имитировало естественный APE-сигнал. В результате мыши начинали чаще повторять то действие (например, выбор определенного выхода), с которым совпадала стимуляция — даже если оно не приводило к награде.
Чтобы исключить вероятность того, что дофаминовый сигнал хвоста стриатума просто отражает начало движения или реакцию на звук, ученые провели серию контрольных экспериментов. В одном из них они убирали звуковую подсказку или переносили ее на другое время — и выяснили, что уровень дофамина в хвостовой части стриатума при этом не менялся. Это показало, что сигнал не связан напрямую со звуком. В другом опыте они давали мышам возможность свободно передвигаться вне задачи и обнаружили, что дофамин в анализируемой области по-прежнему выделялся при определенных движениях, особенно при поворотах в одну сторону, и зависел от их амплитуды. То есть сигнал действительно был связан с действием — но не с его физическими параметрами, а с его контекстом и неожиданностью.
Наконец, авторы построили вычислительную модель, в которой мозг представлен как система с двумя независимыми контурами обучения. Первый использует классическую ошибку прогноза вознаграждения (RPE): он формирует поведение, ориентируясь на награду. Второй — на ошибке предсказания действия (APE): он закрепляет те действия, которые уже были выполнены, даже без оценки их полезности. Отдельно система APE не способна эффективно обучать — она просто повторяет прошлое. Но если сначала обучение идет через RPE, а затем подключается APE, поведение становится стабильным и повторяемым. В модели это сочетание приводило к более быстрому и устойчивому обучению: сначала животное осваивало задание благодаря RPE, а потом APE-сигналы закрепляли удачные реакции в виде привычек.
Это открытие может иметь большое значение для понимания не только привычек, но и расстройств, при которых поведение становится ригидным и плохо поддающимся изменению, например при обсессивно-компульсивном расстройстве или зависимостях. Также оно ставит под сомнение распространенную идею, что дофамин — это исключительно молекула вознаграждения.
Источник

Вам будет интересно
 130
130
 0
0


 158
0
158
0