Меню
Меню





 Все темы
Все темы
Как искусственный интеллект раскрывает все «слои» регуляции генома
В Nature опубликован обзор инструментов искусственного интеллекта, «расшифровывающих грамматику генома». Речь идет о работе с некодирующими последовательностями, которые у человека занимают наиболее обширную часть генома. Если вы сталкиваетесь с ними в своей научной деятельности, может быть, какие-то из этих инструментов станут полезными открытиями для вас?

AlphaFold — модель искусственного интеллекта (ИИ) для предсказания трехмерной структуры белков — называют решением «великой задачи биологии». За решение этой задачи в 2024 году создателям AlphaFold (и не только) присудили Нобелевскую премию по биологии и медицине. Но глобальные задачи биологии не ограничиваются структурой белка — крайне важной и одной из ключевых задач остается выявление роли генетических вариантов. Особенно затруднительна интерпретация вариантов в некодирующей части, которая у человека занимает около 98% всего генома.
Как и зачем пригодится ИИ в анализе некодирующих областей генома?
В отличие от структуры аминокислотной последовательности, трехмерная конформация генома куда менее предсказуема. При этом она может влиять на активность белков в клетке, меняя доступность хроматина и обеспечивая пространственное сближение таких ключевых элементов регуляции, как, например, промоторы и энхансеры, которые в линейной последовательности генома могут быть удалены друг от друга на большие расстояния.
Для работы с такими данными компания DeepMind, известная созданием AlphaFold, представила другой ИИ под названием AlphaGenome. Эта модель глубокого обучения предсказывает, как последовательность ДНК повлияет на молекулярные фенотипы.
Однако существующий набор инструментов на базе ИИ для работы с геномными последовательностями и их функциями выходит далеко за рамки этих двух разработок.
Одна из первых ИИ-разработок в области геномики — DeepSEA — была опубликована в 2015 году вычислительными биологами из Принстонского университета в Нью-Джерси.
DeepSEA представляет собой сверточную нейронную сеть (CNN) — ту же архитектуру глубокого обучения, которая используется для классификации изображений. Эту модель обучили на данных эпигенетики, полученных в рамках проекта ENCODE, — они включали связывание транскрипционных факторов, доступность хроматина и модификации гистонов.
Алгоритм DeepSEA предназначен для прогнозирования эффектов некодирующих вариантов по их последовательности. Он напрямую вычисляет регуляторный код последовательности, опираясь на крупномасштабные данные профилирования хроматина, и позволяет прогнозировать влияние изменений последовательности на хроматин с чувствительностью до одного нуклеотида. В статье, посвященной разработке алгоритма, авторы продемонстрировали его применимость для уточнения классификации функциональных вариантов, таких как локусы количественных признаков экспрессии (eQTL) и ассоциированные с болезнями варианты.
С тех пор эта область пережила бурный рост. Биотехнологическая компания
Calico Life Sciences (Калифорния) приложила руку к созданию нескольких моделей ИИ, многие из которых имеют названы в честь разных пород собак. Среди них —
Akita для прогнозирования 3D-сворачивания генома,
Basset и
Basenji для прогнозирования регуляторных последовательностей и
Borzoi для предсказания профиля экспрессии РНК по всей длине гена. Не все они основаны на сверточных нейронных сетях — Borzoi, например, содержит помимо CNN архитектуру трансформера.
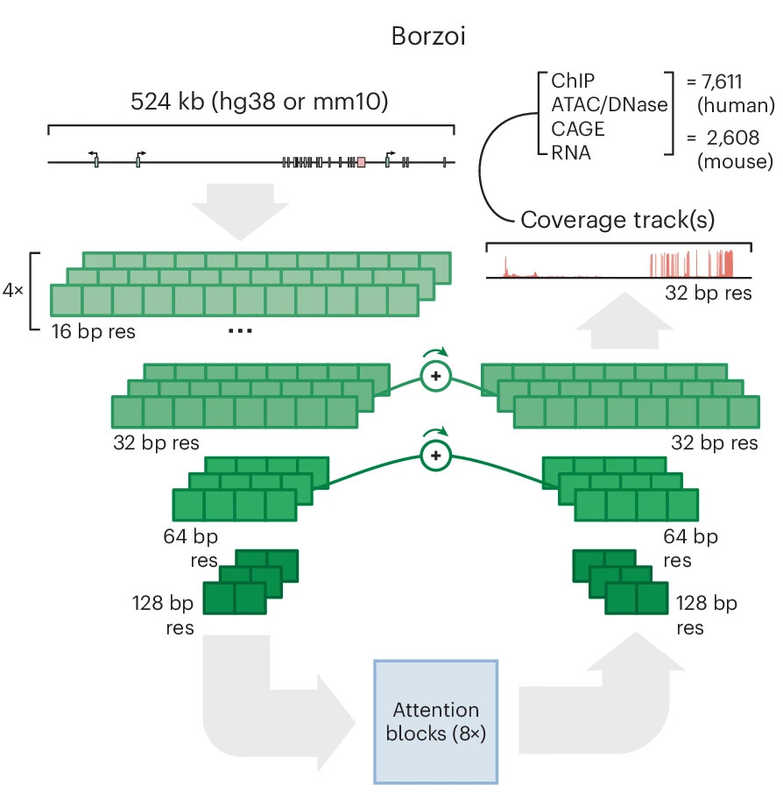 Архитектура Borzoi — модели ИИ для предсказания профилей экспрессии РНК.
Архитектура Borzoi — модели ИИ для предсказания профилей экспрессии РНК.Credit:
Nature Genetics (2024). DOI: 10.1038/s41588-024-02053-6 | CC BY-NC-ND
От этих моделей произошли варианты следующего поколения, более совершенные или узкоспециализированные и тоже названные. Например, Malinois является «потомком» алгоритма Basset, а Scooby — это вариант Borzoi для работы с данными единичных клеток. Другие разработчики создавали собственные модели, названия которых уже не имеют отношения к собакам — например, алгоритм Puffin выявляет промоторные последовательности в геноме. (Впрочем, норвежский лундехунд на английском нередко называется puffin dog, поскольку эта порода собак исторически использовалась для добычи тупиков, так что о полном отсутствии связи с собаками говорить сложно.)
Не только CNN: языковые модели в геномике
Другой класс — это модели, использующие обучение без учителя или самообучающиеся. Это так называемые «геномные языковые модели» (gLM). Как и всем известный ChatGPT, они обучаются на огромных объемах «текста» — в данном случае, геномных последовательностей — и их задача состоит в том, чтобы предсказать следующий нуклеотид («токен») в последовательности или заполнить в ней пробелы, исходя из окружающего контекста.
Одна из таких моделей —
Evo — была обучена на 300 миллиардах нуклеотидов, составляющих геномы различных бактерий, архей и бактериофагов. Она комбинирует архитектуру трансформера с операторами Hyena — такая гибридная архитектура позволяет сократить вычислительное время при высокой производительности и добиться разрешения в один нуклеотид. Следующую версию модели, Evo 2, обучили также на эукариотических геномах: по словам авторов, это репрезентативная выборка, охватывающая всю наблюдаемую эволюцию. Такая модель оказалась
способна идентифицировать границы интронов и экзонов, предсказывать влияние мутаций и генерировать функциональные гены и геномные последовательности с нуля.
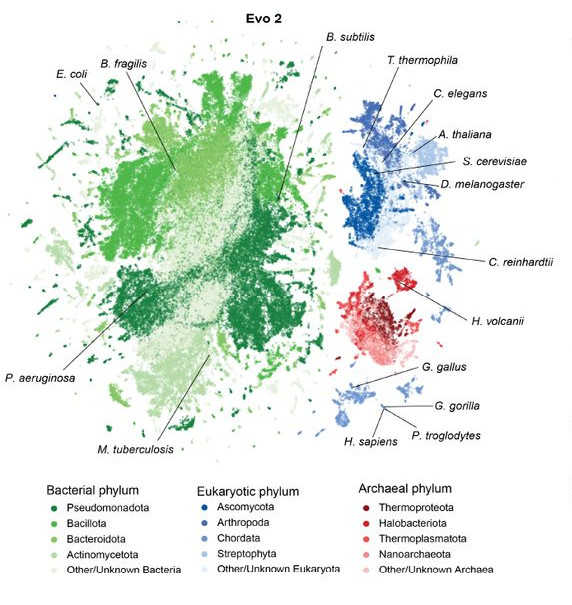 Выборка геномов, на которых обучена Evo 2, охватывает широкий ряд таксонов бактерий, архей и эукариот.
Выборка геномов, на которых обучена Evo 2, охватывает широкий ряд таксонов бактерий, архей и эукариот.Credit:
bioRxiv (2025). DOI: 10.1101/2025.02.18.638918 | CC BY-ND
Модели ИИ для работы с геномными данными также можно различать по типу регуляторных взаимодействий, которые они предсказывают. Модели «последовательность-функция» в основном идентифицируют цис-регуляторные последовательности ДНК, зачастую в отрыве от контекста биологических процессов. Есть и модели, выявляющие транс-регуляцию активности генов — они, например, могут служить для анализа целых генных сетей.
Однако с такими моделями существует своя трудность — как правило, они обучаются на данных об экспрессии РНК и по ним должны делать выводы о причинно-следственных связях. Не всегда их можно раскрыть напрямую, поскольку нет гарантии, что два гена напрямую связаны, если их экспрессия возрастает и снижается одновременно. А даже при наличии связи не всегда очевидно ее направление — регулируется ли ген А геном Б или наоборот? Поэтому такие модели часто ошибаются, если их просят предсказать последствия выключения конкретного гена.
Наконец, возможен и комбинированный вариант — включение в модель как цис-, так и транс-регуляторных элементов. Одной из моделей, в которой они совмещены, является уже упомянутая Scooby — версия Borzoi для работы с данными единичных клеток (go.nature.com/3upffnp). Используя данные о доступности хроматина и транскрипции из одних и тех же клеток, Scooby предсказывает как характеристики последовательности генома, так и состояние клеток.
Впрочем, анализ регуляторных последовательностей, которые сильно удалены от своих мишеней, пока остается нерешенной проблемой. Трудность состоит в том, что несмотря на свою протяженность, геном человека конечен — в нем содержится всего около 20 000–25 000 генов, и лишь небольшая часть из них регулируется в том или ином типе клеток. Из-за этого примеров регуляторных стратегий, на которых может учиться модель, существует относительно мало.
Один из подходов к расширению базы знаний модели — обучать ИИ не только на эталонном геноме, а, например, на совокупности геномов нескольких особей. Такой метод даст модели представление о генетическом разнообразии в пределах вида.
Другой подход заключается в том, чтобы не ограничиваться естественными геномами, а использовать полностью искусственные ДНК. С его помощью авторы статьи в Nature Biotechnology научились предсказывать эукариотические промоторы. Они протестировали около 100 млн случайных последовательностей длиной около 80 пан нуклеотидов и проверили, смогут ли они выполнять роль промотора и обеспечивать экспрессию флуоресцентного белка в клетках дрожжей.
Этот подход имеет преимущество перед использованием геномной ДНК — все сигналы, обнаруженные в случайной последовательности, указывают на причинно-следственную связь напрямую. Если последовательность привела к экспрессии флуоресцентного репортера, значит, она обладает активностью промотора. В геноме, который является продуктом эволюции, такой однозначности куда меньше.
Этот эксперимент с дрожжами позволил сделать два ключевых открытия. Во-первых, он подтвердил, что в регуляторных областях широко распространены биофизические взаимодействия, связанные, в частности, с пространственной конфигурацией участков ДНК. Во-вторых, авторы работы обнаружили, что даже слабые взаимодействия могут оказывать существенное влияние на регуляцию генов — а это, в свою очередь, подчеркивает важность транскрипционных факторов с низкой аффинностью к своим мишеням.
А что насчет других приложений?
Помимо изучения «грамматики генома» и регуляции генов, ИИ можно применять и для точного картирования вариантов — он позволяет установить, какие варианты человеческих генов, выявленные в ходе полногеномного поиска ассоциаций (GWAS), являются причинными для определенного фенотипа. До 95% различий в последовательности, выявленных в ходе GWAS, обнаруживаются в некодирующей ДНК. Также ИИ-инструменты полезны для изучения мутаций in silico, позволяя лучше понять влияние генетических вариаций.
Наконец, геномные модели искусственного интеллекта позволяют и конструировать последовательности ДНК. С точки зрения инженерии, успех проектирования последовательности с нуля показывает, что исследователи (или их модели искусственного интеллекта) получили новые фундаментальные знания о геноме. Кроме того, есть и более прикладные применения — генная терапия или создание контролируемых регуляторов, которые позволят экспериментаторам направленно вмешиваться в клеточные процессы.
Например, с помощью ИИ два исследовательских коллектива независимо друг от друга сконструировали синтетические энхансеры для клеток
Drosophila melanogaster и
человеческих клеток. Обе статьи были опубликованы в Nature в 2024 году. Авторы еще одной работы
сконструировали de novo
целый набор цис-регуляторных элементов, активных в различных клеточных линиях человека.
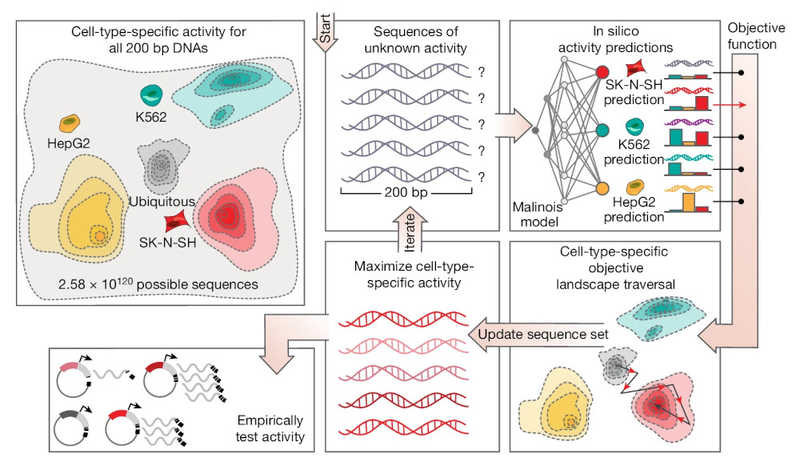 Алгоритм генерации цис-регуляторных элементов для разных типов человеческих клеток.
Алгоритм генерации цис-регуляторных элементов для разных типов человеческих клеток.Credit:
Nature (2024). DOI: 10.1038/s41586-024-08070-z | CC BY
Прикладное применение, например, в генной терапии, потребует более прицельного вмешательства — например, не только в конкретные типы клеток, но и в определенные этапы их развития. Это более сложная задача, однако уже сейчас полученные данные приближают ученых к ее решению. Например, если сайты связывания факторов транскрипции перекрываются между собой, можно внести в эти области генома такие изменения, чтобы функционировал лишь один заданный сайт. Кроме того, в геноме существуют «потенциальные энхансеры», которые можно преобразовать в активную форму, внеся минимальное число мутаций. Это говорит о том, что внесение одного изменения может непреднамеренно активировать ранее неактивные гены.
Что касается применения напрактике, многие исследователи согласны с тем, что ИИ-модели «последовательность-функция» в целом работают так, как заявлено. Но область их применения (а также приложения других моделей) остается предметом дискуссий. Так, несколько коллективов независимо друг от друга пришли к выводу, что геномные модели не справляются с ключевой задачей: объяснить, почему вариации в экспрессии генов различаются от человека к человеку — почему один человек экспрессирует данный ген больше, чем другой, учитывая уникальную констелляцию генных вариантов каждого индивидуума.
Геномные языковые модели, как ИИ с неконтролируемым обучением, во многом упускают многослойную иерархию эпигенетической регуляции, и порой «ломаются» о последствия, которые могут возникнуть при нарушении той или иной последовательности. Эти проблемы еще только предстоит решить, однако — особенно в случае успешного решения — сторонники применения ИИ в геномике видят весьма обширные перспективы.
Источник
Jeffrey M. Perkel. Beyond AlphaFold: how AI is decoding the grammar of the genome. // Nature Technology Features (2025). DOI: 10.1038/d41586-025-02621-8

Вам будет интересно

 4865
4865
 0
0