Меню
Меню





 Все темы
Все темы
Нобелевская неделя 2024. Джон Джампер о включении химической и биологической интуиции в предсказание структуры белка
«Мы решили проверить, какие наши идеи работают, а какие — нет. Выяснили, что каждая была значимой, и ни одна не перевешивала. Мне кажется, что нет никакой “серебряной пули” для внедрения физической или химической интуиции в сеть — есть множество способов сделать это, и каждый из них повышает эффективность». Лекция лауреата Нобелевской премии по химии Джона Джампера. Стокгольм, 08.12.2024.

Отправной точкой для входа в биологию, по словам Джона Джампера, стало то, что он подал заявку на одну работу, а получил совершенно другую — и оказался в лаборатории, которая занималась моделированием белков с использованием очень прямого подхода, основанного на уравнениях Ньютона. Джампер родился в 1985 году в Литл-Роке (штат Арканзас, США). Он получил докторскую степень в 2017 году в Чикагском университете, а сейчас работает старшим научным сотрудником в Google DeepMind.
Какая физика встречается в изучении белков?
Джампер привел отрывок выступления Майкла Левитта (лауреат Нобелевской премии по химии за 2013 год совместно с Мартином Карплусом и Арье Варшелем за «компьютерное моделирование химических систем»). Он прекрасно иллюстрирует, как люди размышляют о включении физики в моделирование белков:
«Представляем белки как набор атомов. Электроны просто отбрасываем и пытаемся заменить их хорошей энергетической моделью, которую можно будет использовать для вычисления сил, чтобы уточнять позиции и наблюдать за движением белков. Это совершенно завораживает. Люди обычно именно так и думают, когда хотят представить себе включение физики в расчеты движения белков. Давайте подумаем о силах, действующих на атомы. А потом сведем их к тому, что знают молодые физики. Возьмем атом водорода, хорошо понятные физические принципы, взаимодействия Ван-дер-Ваальса, кулоновские взаимодействия. И после всего этого люди записывают уравнения, которые вы видите справа».

«Взглянув на них, вы можете увидеть вещи, которые знакомы любому физику. Но если присмотреться повнимательнее, можно понять, сколько физики здесь отсутствует. Например, все эти взаимодействия парные. Это неполярная модель. Но мне больше всего нравится в этих изображениях уравнений то, что они почти все написаны шрифтом Comic Sans. Это выглядит как какой-то грубый и приблизительный взгляд на физику, а ведь так оно и есть».
Джампер отметил, что на самом деле в изучении белков может быть гораздо больше физики, скорее похожей на особую и эффективную модель машинного обучения. Но ее очень-очень дорого использовать. Основная проблема заключается в достижении необходимых временных масштабов для моделирования таких процессов, как фолдинг белка. Даже если удастся их смоделировать в масштабах миллисекунд, когда происходят основные события, можно обнаружить, что модель недостаточно точна. Это требует настройки множества параметров для повышения точности. Многие успешные подходы до AlphaFold и после него опирались на машинное обучение, начиная с ресурсов со стороны физики.
Помогает ли геометрия в моделировании структуры белков?
«Конечно же, мы начали с наблюдений, а именно с банка белковых данных (Protein Data Bank). PDB — невероятный ресурс, и много усилий структурно-биологического сообщества было вложено в то, чтобы данные были доступны, мы могли разрабатывать вычислительные методы и тестировать их. Он растет быстрыми темпами и требует огромных инвестиций. Мы пересекли отметку в 200 тысяч структур в банке данных, и каждая из них — это примерно год работы студента. Это поистине невероятные общественные инвестиции в данные, и они дают нам другой путь решения задачи».
«Одним из самых успешных подходов было начать с большого источника информации, доступного нам. Последовательности белков преобразуются в коэволюционную статистику, которая определяет, какие типы аминокислотных остатков изменялись вместе. Эта информация затем используется для неких прогнозов относительно структуры, а потом отдаются машине для преобразования в структуру с высокой степенью надежности. Наша система AlphaFold 1 была хорошим примером подобного подхода. Это был буквально тот же дизайн нейронной сети, который использовался для проекта компьютерного зрения в DeepMind. Она имела на входе биологические и коэволюционные данные. А выходными были геометрические и физические данные, и эволюционные расстояния между аминокислотными остатками».
Изначальная идея заключалась в том, что данные о коэволюции могут предоставить Джамперу и его коллегам информацию о контактах. В частности, выяснилось, что близко расположенные остатки имеют тенденцию эволюционировать скоординировано. Иногда эти сближенные остатки удавалось идентифицировать. Но в некоторых случаях AlphaFold 1 утверждала, что два остатка находятся на расстоянии 13 ангстрем друг от друга. Это довольно большое расстояние. Это как сказать: «Я абсолютно уверен, что мой друг находится на расстоянии 178 метров». В общем, иногда AlphaFold 1 определяла локальные части структуры, понимая геометрию очень хорошо. Она устанавливала дистанции, в основном измеряя геометрию.
Исследователей сначала сдерживало объединение двух областей, биологии и геометрии, которые имеют мало общего и встречаются непонятным образом. Информация должна была извлекаться из данных, полученных из примерно 140 000 доступных на тот момент структур белков.
Нужна ли эволюционная информация в предсказании структуры белков?
«Мы полностью зависели от общих возможностей обучения наших систем. Как мы можем интегрировать весь человеческий опыт, который у нас есть? Первый этап состоял в том, чтобы создать что-то чрезвычайно простое, где сначала бы обрабатывались одни данные, затем другие, а машинное обучение использовалось лишь частично. Как сделать это простым? Начнем с последовательности слева, встроим большую нейронную сеть посередине, и в результате получим структуру справа. Достижение этой простоты казалось важным шагом. Нам нужен был способ ее реализовать, и центральная часть должна была основываться на физике, химии и геометрии, чтобы эффективно использовать имеющиеся у нас данные».
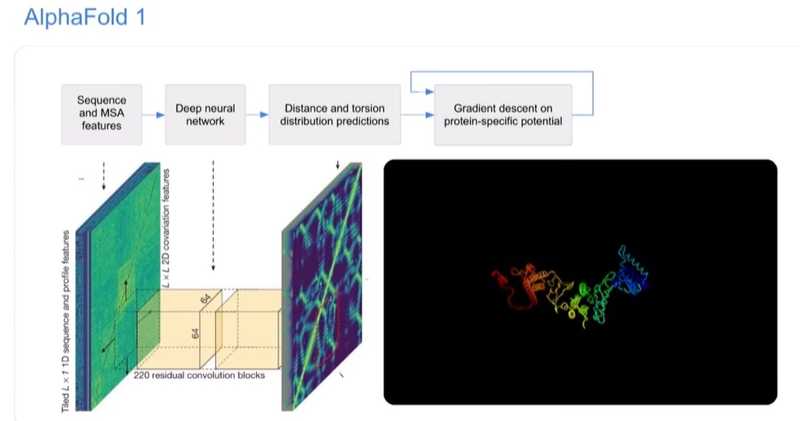
«И вот как мы начали это делать вскоре после выпуска AlphaFold 1 в конце 2018 года. Мы решили — давайте просто выкинем эволюционную информацию. Она хороша, но мы действительно хотели понять физику и геометрию. Поэтому мы вернулись к началу, и это привело к тому, что наша производительность почти для всех белков стала ужасной. Плохие результаты дали нам возможность пробовать необычные идеи, поскольку такая необычная идея могла стать передовой».
Джампер вспомнил, что еще в своей диссертации он работал с концепцией геометрических рамок, согласно которой каждый остаток имеет боковую цепь, отходящую от него. Ее ориентация тоже играет важную роль. Команда начала экспериментировать с предсказанием боковых цепей. Оказалось, что с помощью глубокого обучения можно очень хорошо определить, где находятся боковые цепи. Исследователи поняли, что если взять архитектуру, которая имеет некоторое представление о геометрии, и встроить ее в нейронную сеть, то можно создавать структуры белков напрямую: вводить последовательность и получать ответ в виде структуры.
Как появилась AlphaFold 2?
«У нас была идея, что мы встроим геометрию как инструмент, который сеть будет использовать при создании структур. Но оказалось, что небольшой блок для моделирования фолдинга уже работал удивительно хорошо. Результаты все еще были плохими, но уже выглядели как белки. Было очевидно, что сеть сразу начала обрабатывать геометрию белков. Потом пришла мысль вставить прогнозы расстояний от AlphaFold 1 в эту сеть для предсказания геометрической структуры. И это выглядело очень похоже на структурный модуль финальной версии AlphaFold 2. Мы вводили туда дистанции и почти сразу получали почти такие же хорошие прогнозы, как у AlphaFold 1». Исследователи пробовали множество новых идей для сетей, работающих с геометрией, но так не смогли повысить точность моделирования. Они столкнулись с проблемой, которую назвали «барьером дистограммы» (гистограммы дистанций). И решили построить новые компоненты сети на входе так же, как переосмыслили их на выходе.
Кто такой rawBERT и как Джампер с коллегами смогли преодолеть барьер дистограммы?
«Мы начали заново и впервые попробовали то, что сейчас стало популярным. Наши модели не были достаточно большими или глубокими для предсказаний на основе одной последовательности. Но довольно быстро мы решили, что множественное выравнивание последовательностей (MSA) все еще отлично работает. Оно все еще дает нам много информации об эволюционной истории белка. Мы знали, что это имеет большое отношение к структуре. Как можно использовать это? И мы начали тренировать сети исключительно на них, фактически проводя обучение языковой модели».
Сейчас такая архитектура называется BERT (Bidirectional Encoder Representations from Transformers). Ученые брали «сырое» множественное выравнивание последовательностей с несколькими пустыми секциями и пытались предсказать, какая аминокислота находится в конкретном участке. Нужно понимать многое об эволюции и структуре, чтобы предположить, какие аминокислоты могут находиться в скрытых местах. Сеть BERT работала с сырыми данными MSA и была первой крупной языковой моделью. «И мы назвали её rawBERT. Мы решили использовать аксиальное внимание, которое позволяет всем последовательностям в выравнивании “разговаривать” друг с другом посредством определенного вида усреднения».
Этот подход сразу начал показывать интересные результаты. Его разработчики применили сверточные сети как надстройку — они запускали множественное выравнивание последовательностей, сеть BERT пыталась заполнить пропуски, а затем передавала полученные знания в сверточную сеть. Так ученые преодолели барьер дистограмм.
«Почему бы просто не присоединить это к нашему представлению о геометрии? И поэтому мы добавили структурный модуль, и внезапно у нас появилось сквозное (end-to-end) обучение. Мы подавали на вход почти не обработанные данные — выровненных эволюционных данных, а затем генерировали структуру. По пути мы поручали сети решать вспомогательные задачи. Например, заполнять пропуски в MSA или создавать дистограмму, чтобы поддерживать активность сети, давая ей много задач для решения».
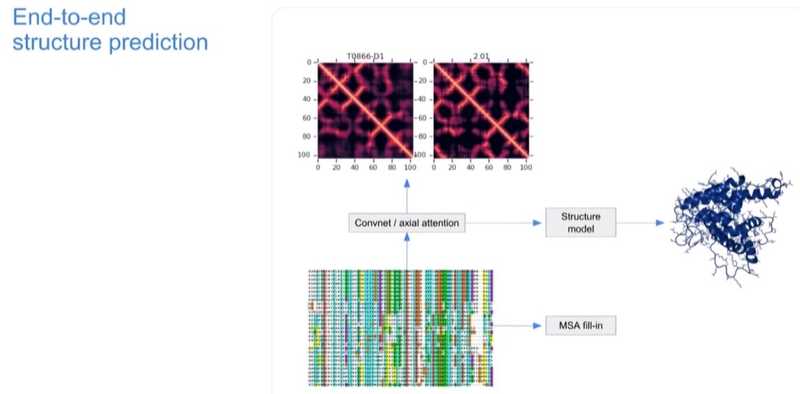
Возможность end-to-end предсказания появилась в середине 2019 года. Эта идея имела два преимущества. Во-первых, она была более точной и согласованной. Во-вторых, это сделало тренировку и тестирование новых идей очень простыми.
«У нас был невероятно креативный период, когда мы могли пробовать множество различных идей и каждый день выяснять, что вчерашняя идея оказалась неверной. Еще одна мысль, которая нам помогла, пришла из статьи, объясняющей, как можно применять внимание к изображениям. Там говорилось, что нужно использовать аксиальное внимание вдоль строк и вниз по столбцам. Мы поняли, что вторая часть обработки, где мы работаем с матрицами аминокислотных остатков, которые в итоге становятся дистограммами, может быть оптимизирована подобным образом».
Как вписать физику и биологию в предсказание структуры белков?
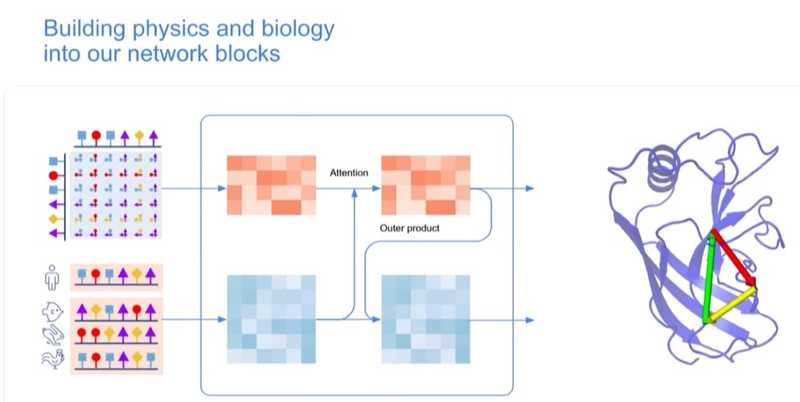
«Как мы можем найти новые способы управления потоками информации, которые отражали бы наше понимание физики и давали бы сети возможность действовать более согласованно с нашими физическими представлениями?» У коллектива появились две хорошие идеи. Одна из них заключалась в том, чтобы уйти от последовательной обработки эволюционной и структурной информации, что было не совсем логично. Ведь ученые стремились рассматривать эволюцию в свете структуры и учитывать структуру в контексте эволюции. Поэтому выходом стало обрабатывать их одновременно. «Мы создали своеобразный диалог между двумя компонентами сети, которые мы называем башнями (two-tower architecture). Этот механизм позволил сети осуществлять более точную обработку информации».
Еще одна интересная идея относилась к обработке пар остатков. «У нас есть I и J как два неких остатка, и могут быть I и K как другая пара. Эти две пары “общаются” друг с другом. Но что насчет третьей стороны треугольника? Почему бы просто не добавить ее? Мы начали добавлять то, что мы называем треугольным вниманием (triangular attention mechanism)». Добавление таких связей повысило точность прогнозов дистанций — они стали примерно в четыре раза лучше согласоваться с геометрией.
Можно ли верить предсказаниям?
Ученые столкнулись с еще одной проблемой, которая заключается не в предсказании структуры, а в понимании, когда она ошибочна. Первой идеей для решения было обучать AlphaFold на тех структурах, которые были предсказаны ей самой, но только на хороших. Они фильтровали и использовали только те структуры или их части, где AlphaFold была действительно уверена в своих выводах. По мере продвижения в проекте, незадолго до того, как были сделаны прогнозы для SARS-CoV-2, разработчики поняли, что нужна функция потерь, которая сообщала бы им или биологам, каким частям этих предсказаний можно доверять. Точность традиционно измеряется показателем pLDDT (predicted Distance Difference Test).
«Мы добавили всего лишь заголовок, который говорит: “Предсказывает pLDDT”. Это приобрело огромное значение после релиза. Помню, биологи активно это обсуждали. Они быстро заметили, что показатели оказались очень, очень надежными и позволяли использовать структуры. Нужно дать знать биологам, которые планируют проводить эксперименты на протяжении дней, недель или месяцев, опираясь в них на предсказанные структуры, верит ли ваша сеть в свои выводы». Финальная идея о том, как измерить надежность, возникла у разработчиков в ответ на комментарий рецензента, который высказал, что предсказание pLDDT — это хорошо, но показатель TM-Score (template modeling score) считается лучшим.
Какая идея больше всего помогает в предсказании структуры белка?
«Когда мы были в процессе написания статьи, то решили проверить, какие идеи работают, а какие — нет. В сообществе машинного обучения это называют абляциями. Мы исключали из решения идеи и проверяли, какие из них действительно важны. Выяснили, что каждая была значимой и ни одна не перевешивала. Мне кажется, это отражает тот факт, что нет какого-то одного универсального решения — «серебряной пули» — внедрения физической и химической интуиции в сеть — есть множество способов сделать это, и каждый из них повышает эффективность».
В конце лекции Джон Джампер поблагодарил команду, с которой работал. Был задействован большой коллектив, в основную группу входило из 15–18 человек, но они получали помощь и поддержку от всей команды DeepMind. Лектор выразил благодарность всему экспериментальному сообществу, в том числе тем, чьи структуры они с коллегами использовали для обучения.

Вам будет интересно

 1422
1422
 0
0


 4865
0
4865
0