Меню
Меню





 Все темы
Все темы
МД-2025: Машинное обучение и инструменты искусственного интеллекта в молекулярной диагностике
Насколько искусственный интеллект можно считать искусственным, и насколько — интеллектом? В чем основная проблема применения ИИ в здравоохранении и как ее решить? Где в машинном обучении применяется бритва Оккама? Чем методы ИИ помогут масс-спектрометристу? Ответы на эти и многие другие вопросы, а также разнообразный опыт применения ИИ — на секции «Молекулярной диагностики 2025», посвященной машинному обучению и искусственному интеллекту.

Первым на секции выступил Евгений Воронин, к.м.н., ФГБУ «ЦСП» ФМБА. Его доклад был посвящен искусственному интеллекту (ИИ) как ключевому компоненту цифровой трансформации.
Говоря об ИИ, необходимо подчеркнуть широту этого термина. В рамках конференции «Молекулярная диагностика» он рассматривается в достаточно большом количестве секций — как минимум для обработки молекулярно-биологических данных, представленных во многих докладах, использовались те или иные математические методы анализа, в том числе ИИ.
Казалось бы, термин «искусственный интеллект» на сегодняшний день общеупотребим и однозначно понимаем. Однако опрос, проведенный в рамках подготовки к этому докладу, показал, что люди вкладывают в один и тот же термин несколько различающиеся смыслы.
Интерес к самому термину растет экспоненциально, с октября 2019 года число касающихся его поисковых запросов возросло примерно 20-кратно. При этом ИИ не является изобретением нынешнего времени, само понятие зародилось около 80 лет назад. С тех пор технологии, связанные с ИИ, пережили минимум два взлета и падения.

Методы ИИ демонстрируют высокую результативность при решении широкого круга прикладных задач, в том числе нечетко поставленных. Важно отметить, что точность ИИ возрастает с увеличением объема данных для обучения моделей. Речь идет о больших данных, или big data, и для хранения таких объемов, очевидно, требуют специализированного подхода к хранению. И здесь мы переходим к понятию центров хранения и обработки данных (ЦОД). Обрабатывать такие данные можно с помощью распределенных вычислительных мощностей — важным инструментом становятся облачные вычисления. И, наконец, эти данные должны откуда-то браться, и взрывной характер роста объема данных во многом связан с развитием интернета вещей — повсеместным внедрением датчиков и систем для автономного сбора информации.

Таким образом, ИИ невозможен без больших данных, они, в свою очередь, невозможны без их хранения и обработки, а накопление больших данных невозможно без интернета вещей. Эта последовательность и формирует цифровую трансформацию, о которой речь шла в заголовке.
Все указанные термины имеют свое наполнение, поэтому правильно будет начать с фундаментальных определений и обеспечить единое понимание каждого из них.
При этом важно, чтобы термины были однозначно закреплены в нормативных документах. Развитие ИИ в России определено Национальной стратегией на основании Указа президента РФ от 10.10.2019 №490, и согласно указу, целью Стратегии является обеспечение ускоренного развития ИИ в РФ, проведение научных исследований в этой области и повышение доступности информации и вычислительных ресурсов для пользователей.
Однако точных определений для ряда терминов в нормативной документации пока недостает, и необходимость их уточнения говорит о том, что в вопросах ИИ мы все еще находимся в начале пути. На неформальном уровне под методами ИИ обычно понимают методы решения нечетко поставленных задач. И, как уже говорилось, их продуктивность во многом зависит от данных. Большие данные характеризуются не только объемом, но также структурой и характером информации. Технологии ИИ могут помочь в том, что сложно за короткое время сделать человеческим разумом — найти достоверные взаимосвязи в огромных массивах данных. Поэтому искусственный интеллект можно определить как очень хорошего помощника для систематизации и обработки данных, избегая при этом заблуждения о его самостоятельности и способности что-то создавать. Иными словами, ИИ — библиотекарь, а не творец.
В заключение докладчик приводит цитату Игоря Анатольевича Соколова, академика РАН и декана факультета ВМК МГУ: «ИИ имеет две ключевые характеристики: во-первых, он не искусственный, а во-вторых — он не интеллект».
Вера Соболева, к.б.н., ФГАОУ ВО РНИМУ имени Н.И. Пирогова, рассказала о применении технологий ИИ в здравоохранении и перспективах их развития.
Основные вызовы и ограничения системы здравоохранения связаны со старением населения, сопутствующим ростом распространенности хронических заболеваний, а также дефицитом кадров и ресурсов. Рост ожиданий населения от качества и доступности медицинской помощи сейчас превышает имеющиеся возможности.
Цифровая трансформация, о которой говорилось в предыдущем докладе, — это качественное, а не количественное преобразование нынешней ситуации. Для решения ее задач утверждено стратегическое направление в области цифровой трансформации до 2030 года и проект «Искусственный интеллект». Этот проект имеет два основных показателя. Первый из них — количество созданных и размеченных наборов данных для ИИ, которое предполагается увеличить с 12 (на 2024-й год) до 72 к 2030-му году. Второй — количество медицинских изделий с технологиями ИИ, интегрированных в клиническую практику (в 2024 году их было зарегистрировано три).
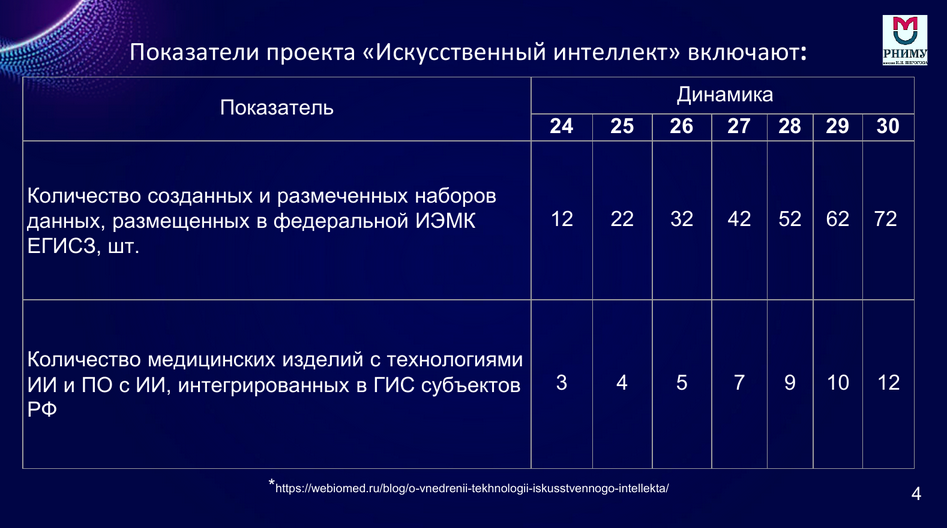
Все разработки, включающие ИИ, можно разделить на две группы — это медицинские изделия для принятия и поддержки врачебных решений и сервисы, обеспечивающие улучшение работы медицинских организаций. Количество зарегистрированных медицинских изделий постепенно возрастает, на конец октября 2025 года в реестре их имелось 89. Наибольшее количество предназначено для анализа медицинских изображений.
Технологии ИИ перспективны в медицине, однако их применение требует правильной постановки задачи и определенного качества данных для обучения и анализа. Здесь возникает серьезное противоречие: имеющиеся данные, содержащиеся в электронных медицинских картах (ЭМК) часто оказываются разнородными, неполными или недостаточно структурированными, а в ряде случаев не соответствуют истине. Иными словами, реальные данные во многом не соответствуют условиям применения ИИ.
Для получения результатов, которые можно будет использовать как минимум без угрозы для здоровья людей, данные ЭМК необходимо привести в надлежащий вид. К решению этой задачи есть два подхода. Один из них состоит в том, чтобы разработать универсальные и централизованно хранимые структурированные медицинские документы, а также создать единый удобный для заполнения и кодирования данных интерфейс. Это обеспечит накопление информации в нужном виде, однако представляет собой долгий и трудоемкий процесс, завязанный на нормативно-правовую базу. Другой подход опирается на обработку естественного языка (NLP) с целью извлечения нужной информации из неструктурированных медицинских записей.
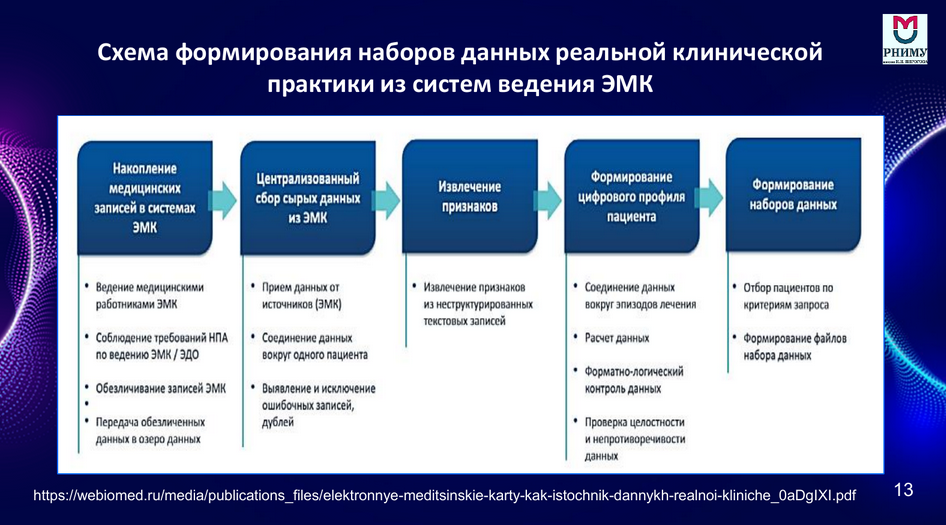
В рамках программы «Приоритет 2030» на базе РНИМУ им. Н.И. Пирогова проведена разработка сервиса для автоматизированного аннотирования медицинских текстов. Созданное программное обеспечение позволяет работать с любой терминологической системой, основанной на различных международных и федеральных справочниках; это решает проблему обратной совместимости.
Таким образом, возможности ИИ для решения задач здравоохранения включают снятие части рутинных операций с врача, сокращение времени и финансовых затрат на обследования, повышение точности решений при ведении массовых случаев. Однако внедрение таких технологий требует грамотной подготовки специалистов, реализации проектов по сбору и накоплению данных, пригодных для обработки методами машинного обучения, и решения ряда этико-правовых вопросов.
Темой следующего доклада стало использование методов интеллектуального анализа данных в количественной оценке влияния нейротрофического фактора мозга (BDNF) на эффективность терапии когнитивных расстройств. Об этом рассказал Олег Сенько, д.ф.-м.н., профессор ФИЦ «Информатика и управление» РАН; ФГБУ «ЦСП» ФМБА.
Исследование, освещенное в докладе, проводилось в течение четырех лет — с 2018 по 2022 г. В него включили 140 пациентов, которых разделили на две группы: 94 пациента получали терапию одним из трех лекарственных препаратов, оставшиеся 46 отказались от него (в основном по экономическим соображением) и составили контрольную группу.
Психическое состояние пациентов оценивалось с помощью набора специализированных тестов, кроме того, их характеризовали по набору биохимических показателей. Целью исследования было установить, как биохимические показатели пациента влияют на результативность лечения, оцениваемую по психометрическим шкалам. Измерения проводили через год, два и три после начала терапии, и по результатам была сформирована единая разнородная база данных.
Анализ данных проводили методом оптимальных достоверных разбиений (ОДР). Статистическая значимость в нем оценивается с помощью известного перестановочного теста в сочетании с принципом бритвы Оккама — более сложная модель может быть применена только в том случае, если она позволяет опровергнуть нулевую гипотезу об исчерпывающем описании наблюдаемых зависимостей с помощью более простых моделей.
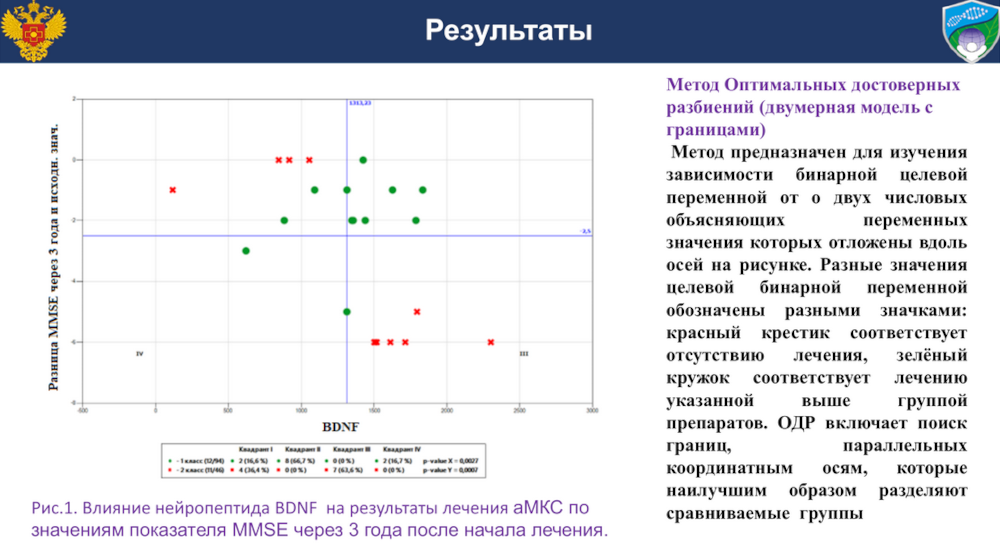
Фактор BDNF, который по результатам исследования оказался ключевым, играл значимую роль только в контексте двух препаратов — мексидол и актовегин. Анализ двумерных закономерностей для пар из биохимического показателя и оценки психического состояния показал, что при низком уровне этого фактора никакой разницы между группами получавших и не получавших лечение пациентов нет. Но если уровень BDNF превышает определенное пороговое значение, психическое состояние нелеченных пациентов значительно хуже, чем получавших лечение. Этот эффект прослеживается практически на всем интервале наблюдений. Всего же из 30 проанализированных взаимосвязей статистически значимыми оказались 13.
Результаты демонстрируют преимущество разработанной методики — она дает возможность находить и описывать достаточно сложные эмпирические закономерности и одновременно оценивать их статистическую значимость. Это позволяет рассматривать методику как близкую к методам ИИ. Ее использование, как и в случае других технологий искусственного интеллекта, требует тесного взаимодействия специалистов с различными компетенциями на всех этапах исследования.
Наконец, клиническая значимость полученных данных состоит в том, что BDNF как биохимический фактор значимо влияет на результаты лечения мягких когнитивных нарушений такими нейропротективными препаратами, как Мексидол и Актовегин.
Методам искусственного интеллекта для расширения возможностей хромато-масс-спектрометрии посвятил свое выступление Юрий Костюкевич, д.х.н., доцент Сколковского института науки и технологий. Группа масс-спектрометрии Сколтеха занимается практически всеми приложениями хромато-масс-спектрометрии — ведь если есть метод, измерить им можно что угодно. Флагманский проект группы — это определение наркотических препаратов в сточных водах школ Москвы. Это один из наиболее удобных в данном случае подходов, поскольку «ловить за руку» школьника, употребляющего психоактивные вещества, затруднительно, но пользоваться туалетом он будет в любом случае, что и позволит выявить факт употребления.
Хромато-масс-спектрометрический анализ включает в себя пробоподготовку, хроматографическое разделение, ионизацию, собственно масс-спектрометрию. Промежуточный этап — фрагментация молекул перед получением масс-спектра — важен для достоверной идентификации, поскольку спектр фрагментации формирует своего рода «отпечаток пальца» соединения. Наконец, полученные характеристики (дескрипторы) сопоставляют с имеющимися базами данных, чтобы установить, с каким соединением исследователь имел дело изначально.
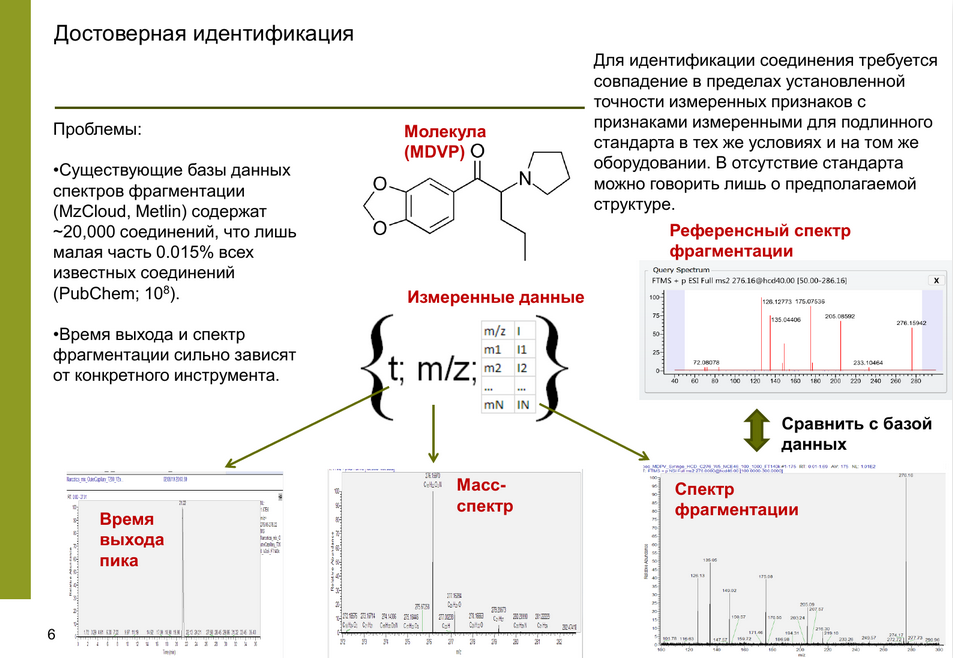
Как методы ИИ помогут в этой области? Прежде всего, с их помощью можно предсказывать любые скалярные параметры, такие как время выхода из хроматографа (время удержания) или продукты фрагментации. Возможно и восстановление исходной структуры по спектру фрагментации.
Однако все современные методы машинного обучения опираются на векторные данные, и возникает вопрос, как представить молекулу в виде вектора. Для этого существует определенное количество способов, и надо сказать, что эти подходы не новы. Один из примеров — QSAR, с помощью которого пытаются предсказывать медицинские свойства препарата по его химической структуре и уже полученным экспериментальным данным.
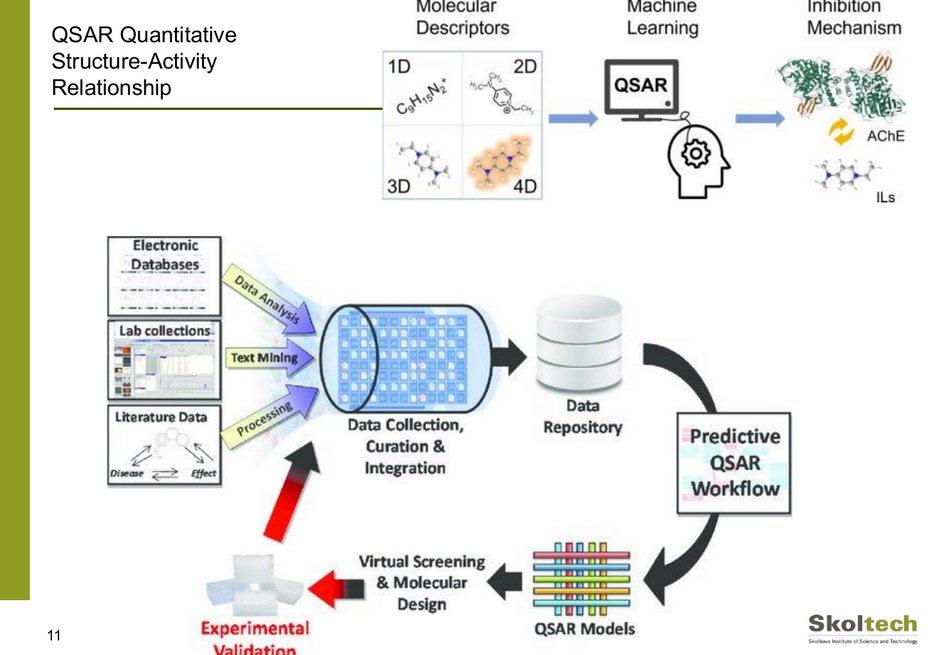
На то, чтобы собрать известные базы данных в одном месте и обеспечить удобство пользования ими, направлена недавно разработанная российская платформа Syntelly. Она создана для того, чтобы оценить параметры того или иного соединения с помощью моделирования, не прибегая к долгим и дорогостоящим экспериментам.
Для одного из важных технических параметров — времени удержания молекулы — сейчас разработана высокоточная предсказательная модель, выдача которой сравнима с реальными экспериментальными данными. Можно сказать, что дальше ее улучшать некуда, поскольку ошибка модели связана с разбросом в экспериментальных данных , и ее исправление потребует уже исправления датасета.
Также современные методы позволяют предсказывать уже упомянутый спектр фрагментации и использовать эти данные для анализа тех или иных характеристик молекулы. Это важно, в частности, для того, чтобы изучать высокотоксичные или запрещенные соединения без необходимости их синтезировать. Обратная задача — определение структуры молекулы по ее спектру фрагментации — также частично решена на сегодняшний момент, и над ней продолжают работать. Наилучшим инструментом на данным момент считается немецкая разработка SIRIUS6.
Наконец, появляется подход, который в перспективе позволит проводить количественные измерения без стандартного образца, который сейчас необходим для количественного анализа. Однако достоверное предсказание эффективности ионизации, предположительно, позволит обойти этот этап, что упростит и ускорит хромато-масс-спектрометрический анализ.
Дарья Соколова, аспирант Центра нейробиологии и нейрореабилитации имени Владимира Зельмана, рассказала об анализе липидных маркеров успешного старения с помощью машинного обучения.
Известно, что средняя продолжительность жизни во всем мире увеличивается, однако это не означает, что улучшается качество жизни пожилых людей. Сохранность когнитивных и физических характеристик на высоком уровне присуща некоторым долгожителям, однако их доля не так высока, а сами популяции долгожителей довольно гетерогенны.
Определить сохранность долгожителей можно с помощью комплексной гериатрической оценки, которая использует набор опросников и шкал.

Российский геронтологический научно-клинический центр изучает московскую популяцию долгожителей, но, как уже говорилось, они бывают разными. По типу старения — от патологического до оптимального — выделяют пять групп. Между этими крайними группами лежит континуум промежуточных состояний.
Можно ожидать, что эти группы старения отличаются на молекулярном уровне. В данной работе в качестве биомаркеров использовались липиды плазмы крови. Для исследования Российский геронтологический НКЦ собрал большую выборку долгожителей — 2380 человек в возрасте от 89 до 107 лет, а в контрольную группу вошли лица 18-89 лет (всего 624 участника).
Образцы плазмы крови всех участников исследовали с помощью масс-спектрометрии, которая предоставляет гораздо более полные данные о разнообразии липидов, чем стандартные биохимические тесты.
Сравнение групп старения между собой выявило ряд отличий в липидных профилях. Больше всего разницы было между группами патологического и оптимального старения.
Наиболее яркие отличия обнаружились в группе короткоцепочечных и полиненасыщенных триацилглицеридов, уровень которых был повышен в группе оптимального старения и снижен при патологическом. В остальных группах они формировали плавный градиент.
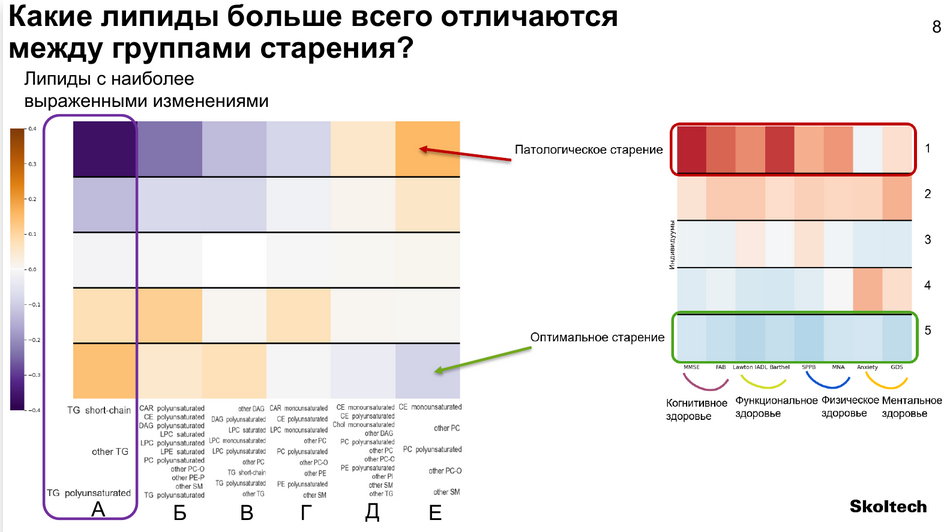
Включение контрольной группы (до 89 лет) дает возможность оценить, как уровни липидов меняются с возрастом, и соотнести эту динамику с возрастными изменениями.
Самые выраженные и самые интересные, по словам докладчицы, различия также отмечались среди короткоцепочечных и полиненасыщенных триацилглицеридов. Выявленные различия, сопоставленные с данными комплексной гериатрической оценки, позволяют разделить группы старения по липидному профилю, что в перспективе позволит предсказывать общую динамику возрастных изменений.
Опытом изучения гетерогенных патологий с применением ИИ поделилась Анна Яковчик, ФГБУ «ЦСП» ФМБА России, рассказав об этом на примере шизофрении.
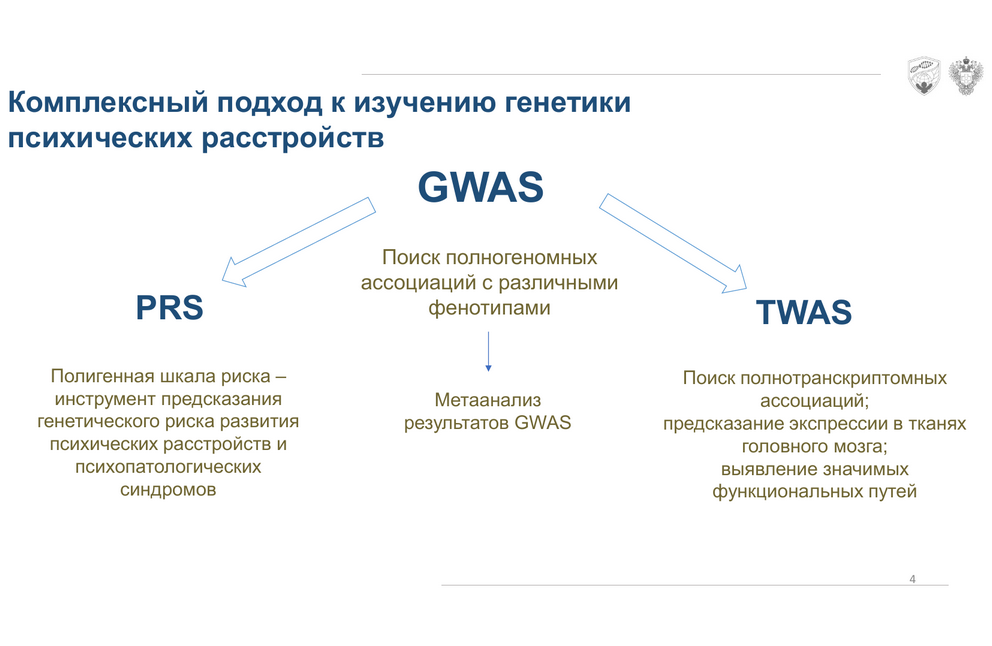
Одна из трудностей генетических исследований в области психиатрии состоит в том, что психические расстройства имеют полигенную природу, и многие генетические варианты связаны не с конкретным расстройством, а с повышенным риском целого их ряда.
Полигенные шкалы риска — перспективный, но пока недостаточно надежный для клинической практики инструмент. Полногеномные поиски ассоциаций (GWAS) уже выявили множество значимых вариантов, ассоциированных с тем или иным фенотипом, например, для шизофрении сейчас известно 287 локусов. Однако такие исследования требуют больших выборок, которые зачастую классифицируют участников только по наличию или отсутствия диагноза. Для таких гетерогенных заболеваний, как шизофрения, это может быть неоптимальным подходом. Формировать однородные группы позволило бы подробное клиническое фенотипирование, кроме того, в ряде случаев имеет смысл выходить за рамки конкретной нозологии и анализировать конкретные клинические проявления, а не обобщенную группу диагнозов.
Сотрудники ЦСП разработали комплексный подход, позволяющий выйти за рамки полногеномных ассоциаций. Он включает предварительное клиническое фенотипирование, которое позволит сформировать несколько однородных групп. GWAS-исследования в таком случае дают много результатов, чтобы их систематизировать, необходим этап метаанализа. Затем по полученным данным можно строить полигенные шкалы риска и проводить полнотранскриптомные исследования, которые позволят определить ключевые функциональные пути, затронутые патологией. Для таких исследований в ЦСП создали свою платформу, основанную на распределенных вычислениях. Вычислительный кластер сейчас состоит из 24 машин.
Проведенный в рамках данного исследования анализ охватил более четырех тысяч пациентов с шизофренией. Одна из подвыборок, выделенных по результатам клинического фенотипирования, включила 817 пациентов с наиболее узким фенотипом — достаточно ранняя манифестация заболевания, классические симптомы, вегетативная симптоматика и социальная дезадаптация. Также в исследование были включены пациенты с другими нозологиями и разнообразными клиническими проявлениями. Группа контроля была сформирована по базе данных популяционных частот генетических вариантов в РФ; в нее вошли 8955 человек, не имевших психоэмоциональных нарушений по данным скрининга.
Полногеномное секвенирование всех участников с 30-кратным покрытием и GWAS для узкого фенотипа шизофрении выявил 87 значимых полиморфизмов. В дополнение к узкому фенотипу аналогичным образом проанализировали другие однородные выборки. Кластеризация полученных данных с применением алгоритма UMAP показала, что наследственная шизофрения с началом в детском возрасте представляет собой отдельную группу с неким общим генетическим «ядром». Аналогичные результаты — общее «ядро» для определенных проявлений — были получены при анализе психопаталогических синдромов, таких как бредовые состояния или суицидальное поведение.
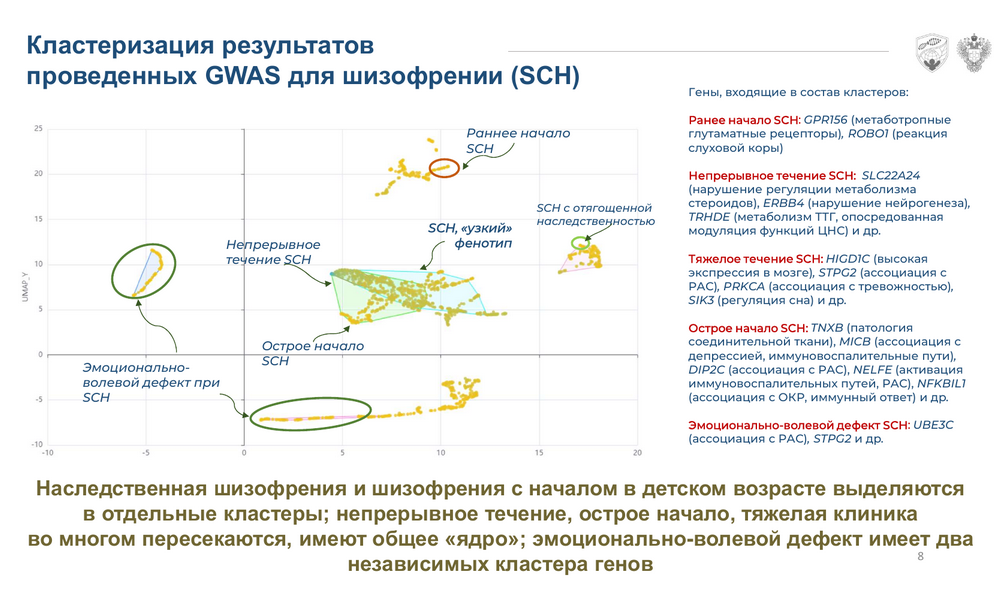
Следующим этапом исследования стал полнотранскриптомный поиск ассоциаций (TWAS) с узким фенотипом шизофрении по всем отделам мозга. Выявленные изменения экспрессии генов в коре больших полушарий указывают на возможную дисфункцию митохондрий и замедление активации микроглии. Анализ также показал, что общие для фенотипа механизмы затрагивают синапсы и, в частности, потерю аксонов, также они связаны с активацией воспаления и апоптозом. Такие же результаты были получены при объединении GWAS и TWAS в единый анализ.
Полигенные шкалы риска по полученным данным могут служить инструментом скрининга. В данной работе их построили по 19 однонуклеотидным полиморфизмам, выявленным при GWAS-анализе узкого фенотипа шизофрении. Внешняя валидация на когорте из 130 контрольных участников и 126 пациентов с шизофренией показала значение под ROC-кривой 0,68, что, по словам докладчицы, достаточно неплохо. Значение ROC AUC на внутренней выборке составило 0,88.
Также исследователи построили полигенные шкалы риска для пяти больших групп синдромов — в перспективе они могут быть полезны для стратификации генетического риска, позволяя предсказать, какие клинические проявления могут доминировать у пациента с тем или иным генотипом.
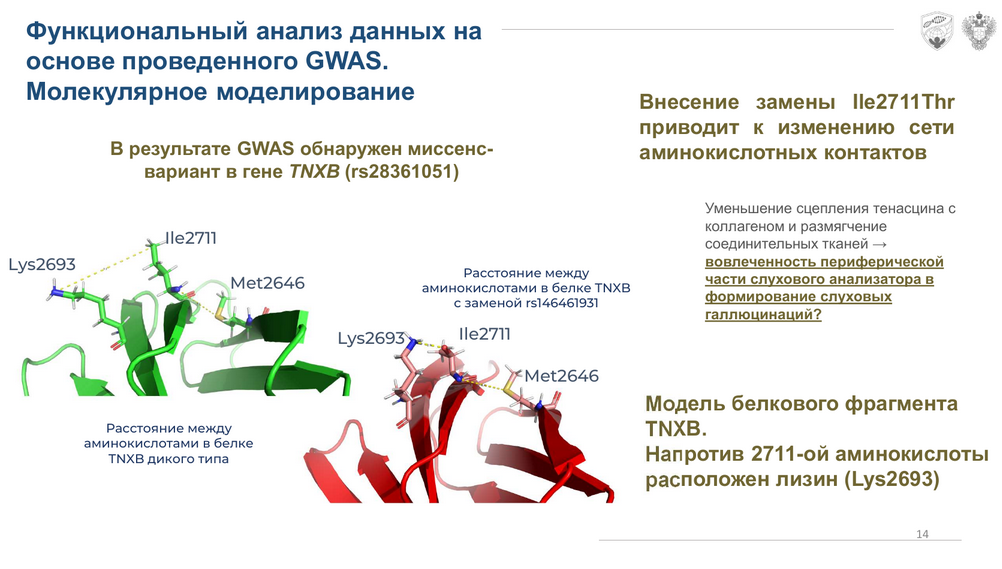
Наконец, предложенный подход обеспечивает возможность для функционального анализа. Клиническая аннотация вариантов, выявленных в ходе GWAS, и молекулярное моделирование уже навели исследователей на предположение, что мутация в гене TNXB, обнаруженная у пациентов, может объяснять вовлечение периферии слухового анализатора в развитие слуховых галлюцинаций при шизофрении.
Еще одно важное направление, для которого ИИ служит ценным инструментом — это диагностика онкозаболеваний. Данной теме был посвящен заключительный доклад в секции, прочитанный Иваном Мешковым из ФГБУ «ЦСП» ФМБА.
Рак легкого лидирует по распространенности во всем мире по данным на 2022 год, в России он находится на третьем месте, что делает диагностику этого заболевания и отслеживание состояния пациентов крайне актуальными задачами. Один из перспективных методов для этого — жидкостная биопсия, а именно анализ внеклеточной ДНК, циркулирующей в плазме крови. Уже показано, что так называемый фрагментомный профиль, то есть особенности набора коротких (80-100 пар нуклеотидов) ДНК в крови служит диагностическим и прогностическим маркером для многих видов рака.
В настоящее исследование включили 286 человек, из которых у 138 был диагностирован рак легкого разных стадий. После выделения свободно циркулирующей ДНК (сцДНК) из плазмы крови и высокопроизводительного секвенирования проводилась биоинформатическая обработка полученных данных. Затем на основе алгоритмов машинного обучения был создан классификатор, который предсказывал статус пациента.
Для анализа геном разделили на неперекрывающиеся окна протяженностью 100 килобаз, на которые картировали полученные фрагментомные данные, в первую очередь концевые участки. Анализируемые фрагменты представили в виде позиционно-весовых матриц (ПВМ).
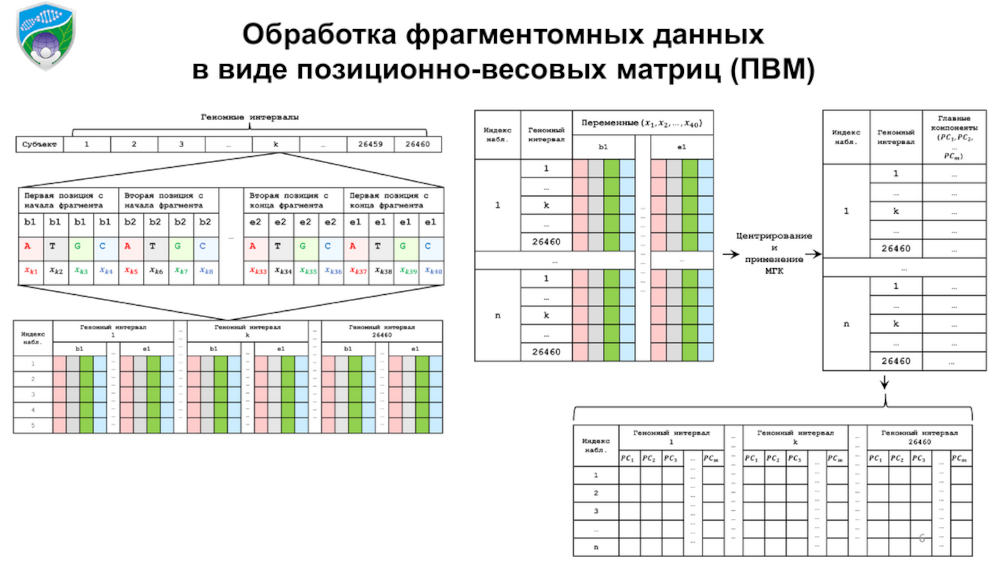
Задачу снижения размерности исследователи решали оригинальным способом — для каждого субъекта и для каждого геномного интервала получали реперный набор данных в дополнение к тренировочному и тестовому. Построенные по этим реперным данным специальные матрицы (по столбцам они включали характеристики ПВМ, а по строкам — геномные интервалы) сопоставляли между пациентами и проводили анализ главных компонент. На основе этого метода составлялись паттерны фрагментации и линейные комбинации этих элементов, то есть главные компоненты, что и позволило снизить размерность.
Далее авторы применили метод метамоделирования — они проводили анализ при помощи целого набора моделей, а полученные предсказания объединяли в матрицу, на основании которой затем формировали модели второго этапа и проводили построение классификатора. Его точность, то есть площадь под ROC-кривой, составила 0,87 на тестовой и реперной выборках и 0,99 — на тренировочной.
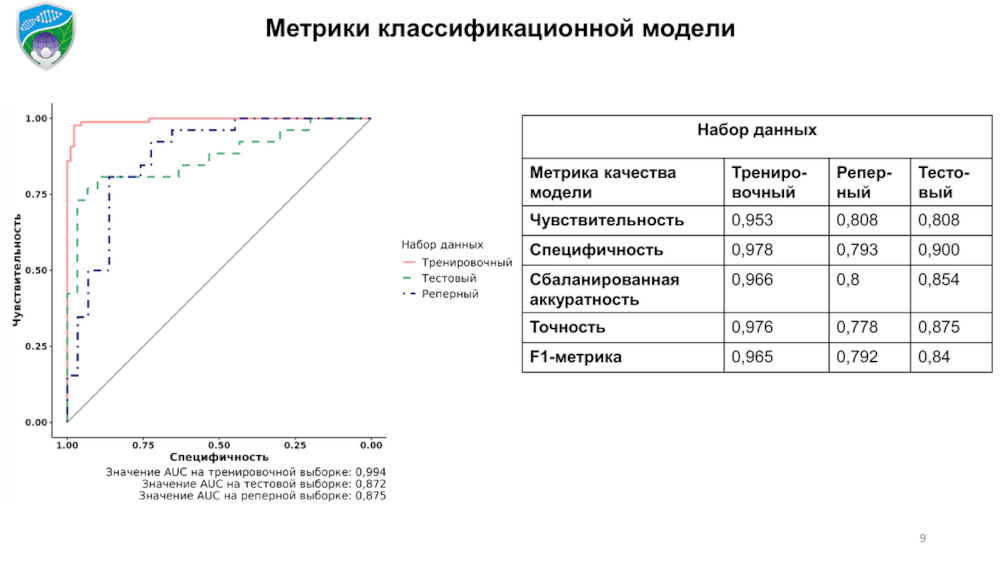
Проверка воспроизводимости и повторяемости полученного классификатора показала, что результаты предсказаний не зависят ни от самого проведения лабораторного анализа (это говорит о воспроизводимости), ни от дня, в который одна и та же команда исследователей проводит анализ (это показатель повторяемости).
Это наглядно демонстрирует, как на основе алгоритма машинного обучения можно создать способ выявления рака легкого по данным секвенирования сцДНК.
Информация о докладчиках
Воронин Евгений Михайлович, к.м.н., ФГБУ «ЦСП» ФМБА, г. Москва
Соболева Вера Владимировна, к.б.н., ФГАОУ ВО «Российский национальный исследовательский медицинский университет имени Н.И. Пирогова» МЗ РФ, г. Москва
Сенько Олег Валентинович, д.ф.-м.н., профессор ФИЦ «Информатика и управление» РАН; ФГБУ «ЦСП» ФМБА России, г. Москва
Костюкевич Юрий Иродионович, д.х.н., Сколковский институт науки и технологий, г. Москва
Соколова Дарья Дмитриевна, аспирант Центра нейробиологии и нейрореабилитации имени Владимира Зельмана, Сколковский институт науки и технологий, г. Москва
Яковчик Анна Юрьевна, ФГБУ «ЦСП» ФМБА России., г. Москва
Мешков Иван Олегович, ФГБУ «ЦСП» ФМБА, г. Москва





 0
0